Part 1
- Everyone gets a blank card/paper.
- Collect Name, Height, Favorite Snack from 3 peers.
- Discuss how it felt to collect primary data.
Part 2
Downloaded dataset:
⬇ Download student dataset
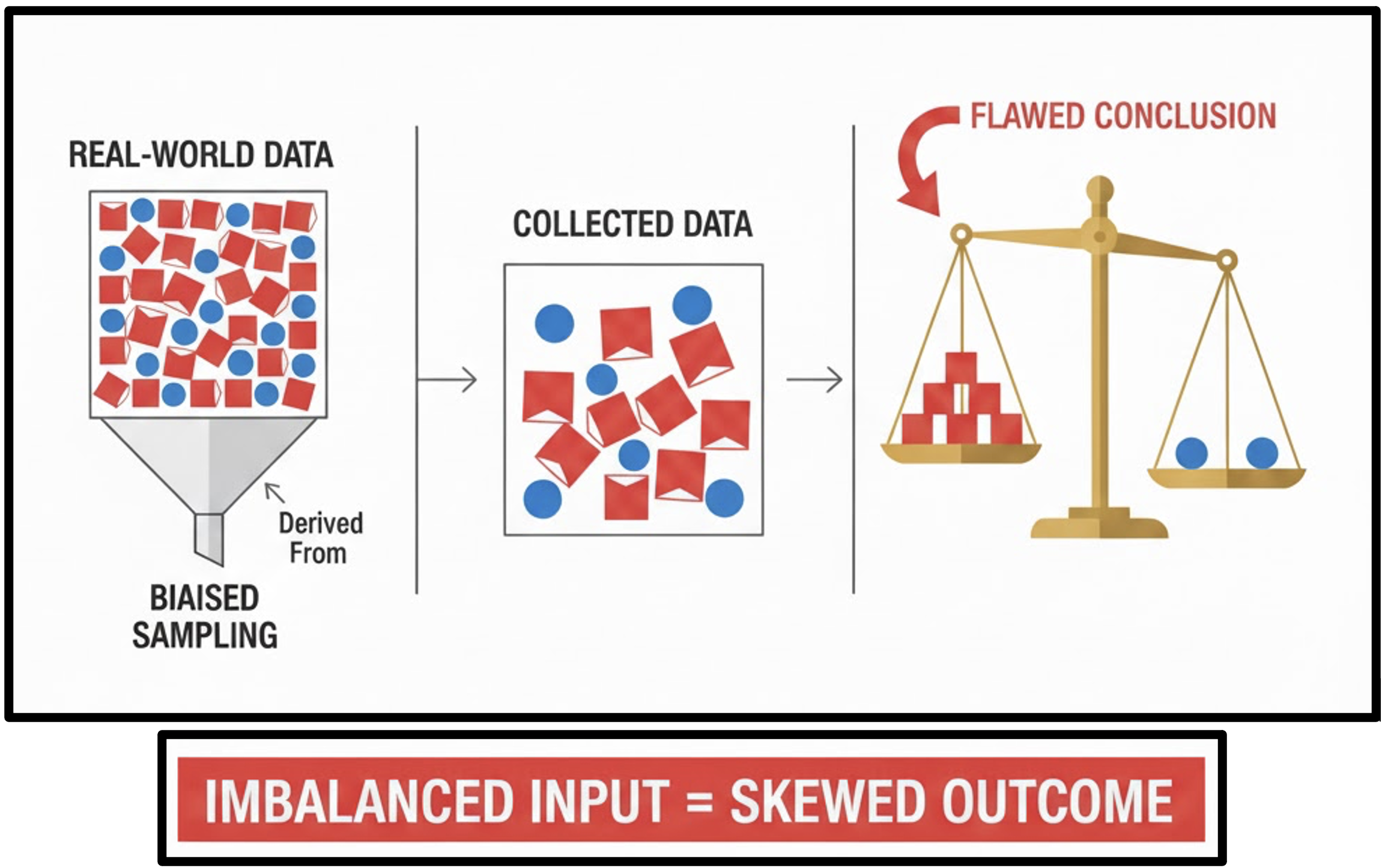
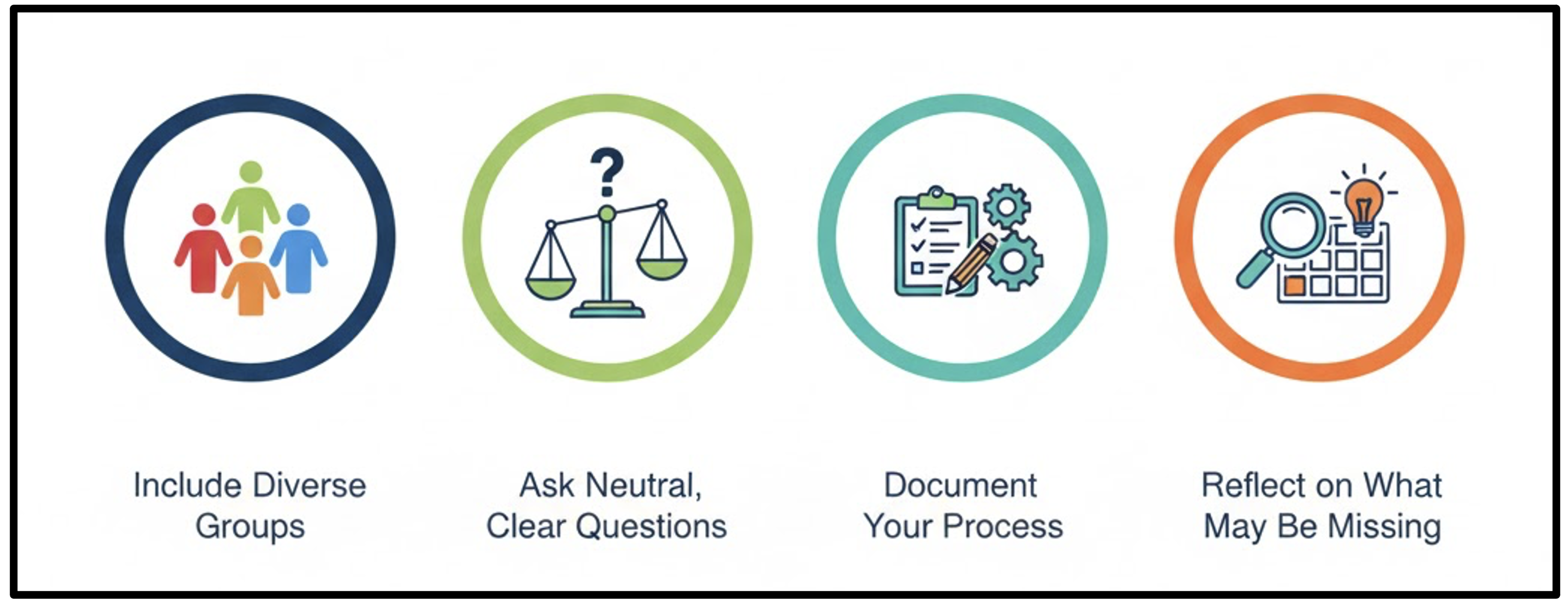
Compare collected primary data vs provided secondary dataset. Does it feel the same to be given secondary data?
Variables: Name, Gender, Age, Favorite Snack, Height, Home Country, Steps Walked (Yesterday), Library Usage (per week), Commute Time, Campus Transport Method, Hours Slept (Avg. per night), Student Status, Participation in Clubs/Societies, Frequency of Healthy Meals, Postcode, IMD Score